Some Thoughts
I have been through a rough week and while I have not finished my Machine Learning homework (I still have about two hours so I’m fine I think) I decide to write about what have happened since my last serious writing on this blog (which is a long long time ago).
I am having trouble executing my weekly plan right now because there are always something that would mess up my sleep timer. But thanks to COVID I can sleep during class time and use another time to watch the recording. Actually that makes my class easier in some ways, since I always find classes too slow and got bored really easily and now I can just speed the recording up.
Since March I have been spending time on a project named Cachecash (link in my about page if you are interested), and it was a hard time at first understanding anything at all. But reading the dissertation was fun, and now I work for no pay at a Indian start-up who uses the project’s code base. It would be my first official CS-related internship but I do not really feel the work tension, might because of the remote working thing or because of the start-up being in its early phases and only a few people are full-time employees. I am trying my best fitting my schedule in but I guess I still cannot make it up to what the company expected. They are ambitious, which is putting me under some stress. I like the job overall.
So this semester I am a TA (finally). It was kinda surprising that professor chose to reach out to me instead of other A students (about eight of them), but I know I deserve it. Overall that’s good and gosh that’s good pay too.
I am tutoring OS in Trio program now, and that’s fine. OS in my opinion is fairly easy, might due to my early history messing with different OS when I was about 12 and experiences in Hackintosh. Although I did not really understand much at that time, it helps.
I recently learned a word called “quarter-life crisis” and I think I am having one right now. As a junior, I can already see the end of my undergrad life while I have no sense where I should go after. Maybe MS or even PHD but gosh 5-7 years? It’s gonna kill me. I know I would regret straightly going into corporate world and there is no such thing as “go for a job then come back for higher degree” for me. I would definitely be stuck on the dollar sign and never let it go. Besides, even though I love computer science and I know many different fields that may interest me, still I can only select one once I choose to go to a grad school right? I don’t want to be the guy who spent two years learning how to fix pagers in 2000 (my father told me one of his friend did).
Peer pressure is high too when most of my friends are getting offer from FB, MS, Google, you name it. THe rest of them are getting into BSMS as well. I fucked up my freshman year or I would do BSMS as well. I know I would regret this for the rest of my life but there is no one to blame on. Ah geez every time I throw back I wanna throw up.
Ok. Tech thoughts:
After reading Robert Collins’ blog about his experience in Cachecash back when they were a start-up, I was little bit frustrated because of the speed issue they could not fix; I mean they were MIT scholars and they couldn’t do it, which putting me into little chance to fix it. But this comes to my mind yesterday:
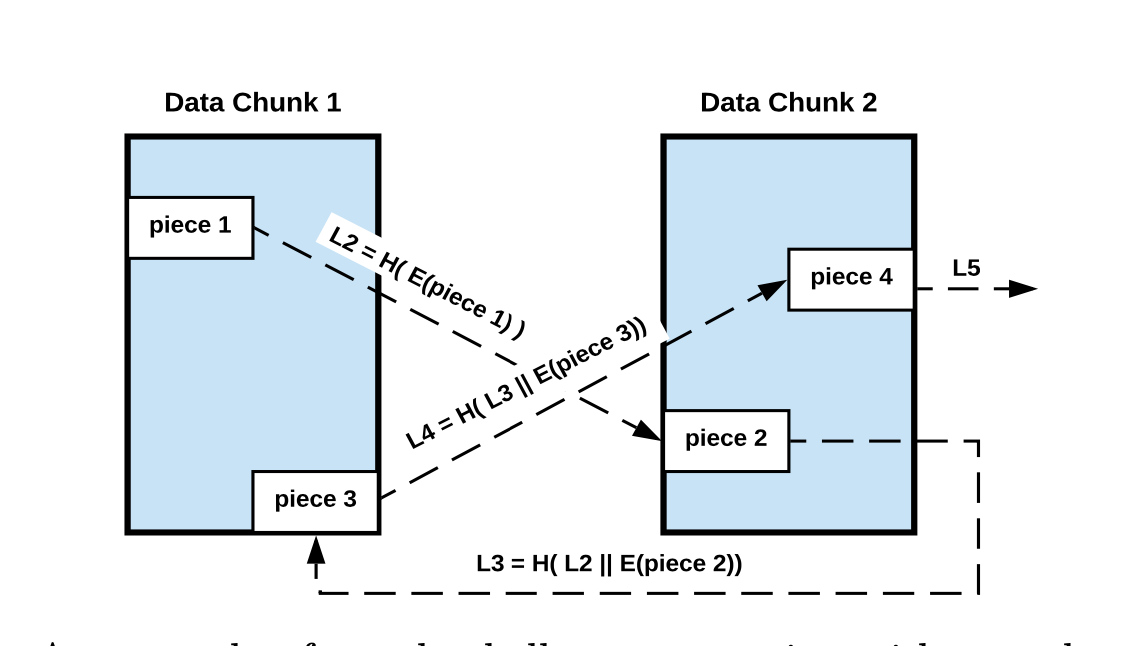
So normally, according to Cachecash protocol, a client would have to brute force through the colocation puzzle to gain trust from publisher and cache, and that is the part using most resources, both computing and bandwidth. In order to get faster, Nicole from the Indian start-up BlockDeliver found out the easiest way is to make the chunk bigger. Understandable, when the data chunk is larger, the number of bundles needed is smaller, hence less transactions and transmissions will happen. Ok. Less chucks also means less colocation puzzle steps will be required to brute force through to get the solution. Like this:
"CAPNet ScreenShot"
But what if, let’s say theoretically, instead of looking for a simpler, less secure hashing algorithm to boost the speed, we let the publisher handle a part of the colocation puzzle. So instead of running between the chunks, we put a location puzzle in a single truck then return to the publisher a hash to the solution. In order to confirm every chunk is received, each chunk will be cut into different size between 1024 to 2048 bytes to ensure speed. The size cut will be a secret key only publisher know so if every chunk has returned the hash and all verified, publisher will determine if the size cut is the same, and then confirm the escrow to the cache.
But all those are just some random thoughts, I will look into it once I can.
Back to ML homework buddie.